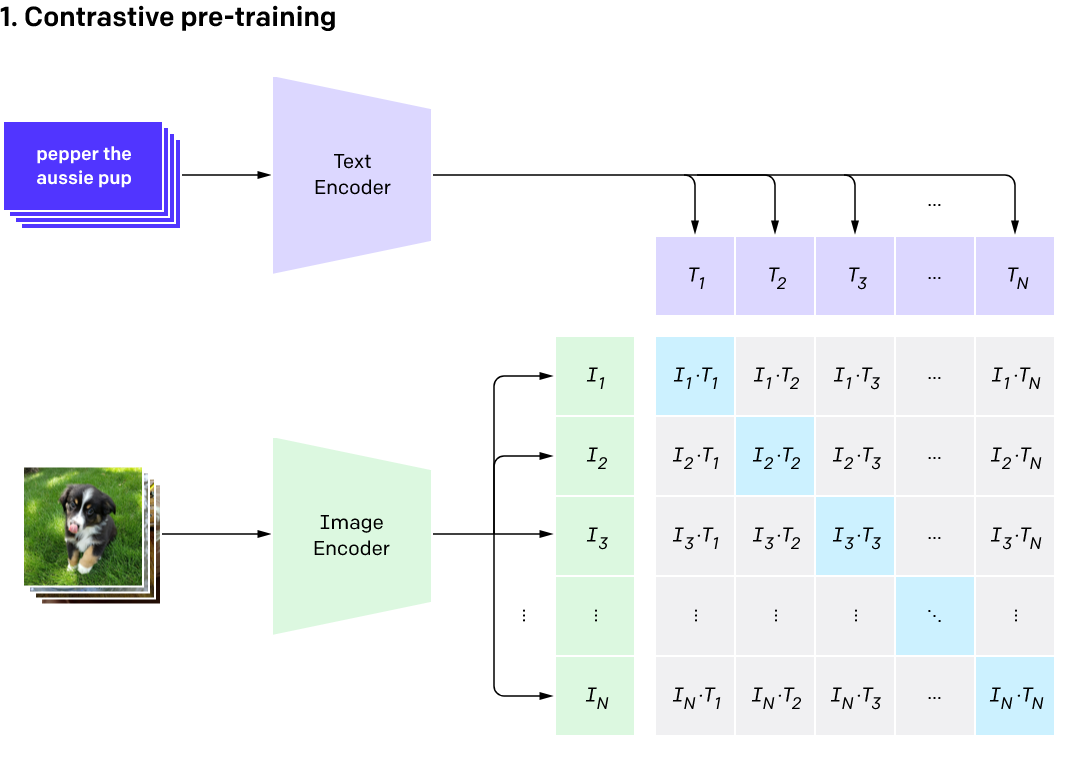
Vision-language models aim to integrate information from both visual and textual modalities, allowing them to understand and generate content that involves both modalities. Vision-language models play a crucial role in advancing the capabilities of AI systems by enabling them to understand and generate content in a more comprehensive and human-like manner. Their importance lies in their ability to bridge the gap between visual and textual modalities, opening up new possibilities for tackling a large variety of vision problems, including generative AI, open world recognition, and scene understanding.
If you are interested, please fill this form!
Slides from the introduction lecture can be found here.
Date: TbD
Location: Virtual event. Zoom link and password will be shared via email.
Lecturers: Prof. Dr. Laura Leal-Taixé, Orcun Cetintas and Jenny Seidenschwarz.
ECTS: 5
SWS: 2
Students are supposed to register to the Matching-System. See the Matching-System FAQ for more details.
After the final matching is announced, we will send an email with further information.
Once the matching process is complete, you will be able to access the papers on the webpage.
TBD


